-
[AI] Optimization(최적화)AI 2023. 4. 3. 22:08728x90
Optimization
최적화는 신경망 분야에서 손실함수의 값을 최소화하는 Hyper Paramter의 값을 찾는 것을 말합니다.
(Hyper Parameter : 사용자가 직접 정의하는 Parameter)
Batch Size, Learning rate 등 모델에 관한 Hyper Paramter를 말합니다.
최적화 방법으로 대표적으로 확률적 경사하강법(Stochastic Gradient Descent, SGD)가 있습니다.
2차 함수가 있을 때, Learning rate(lr)을 따라 하강합니다.Learning rate는 Hyper Paramter로, Learning rate가 작으면 하강하는 속도가 느려져 학습을 시키는데 시간이 많이 걸리고, Learning rate가 너무 크면 하강하는 폭이 커져서 학습이 발산적으로 이루어집니다. 적절한 Learning rate를 주어야 합니다.
Generalization
학습 데이터와 input data가 달라져도 출력에 대한 성능 차이가 나지 않게 하는 것을 일반화라고 합니다.
모델은 Training data를 가지고 모델링을 합니다. 모델링을 하는 목적은 Training data가 아니라 다른 외부의 data를 모델에 입력해도 Training data로 모델을 학습시켜 얻은 Accuracy와 비슷한 값을 가지게 하는 것이 목적입니다.
일반화는 다른 외부의 data를 넣어도 Training data로 모델을 학습한 것과 거의 비슷한 결과를 얻는 것을 말합니다.
즉, 일반화 성능을 올리는 것이 목적입니다.
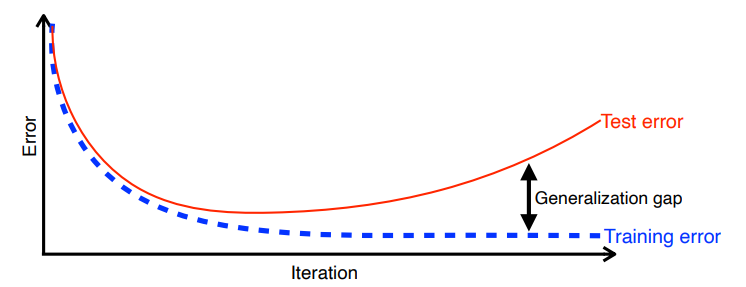
학습 iteration이 지나갈 때 마다 학습 데이터의 train error는 줄어듭니다. 하지만 train error가 0이 되었다고 해도 우리가 원하는 최적 값에 도달했다는 보장은 없습니다.
시간이 지나면서 학습에 사용하지 않은 데이터에 대해 성능이 오히려 떨어지게 됩니다.(= Test error)
"일반화 성능이 좋다"는 학습에 사용하지 않은 데이터에 대한 Test error와 Training error의 차이가 적은 것을 의미합니다.
Underfitting vs Over fitting
Underfitting
네트워크와 train이 너무 간단해서 학습 데이터도 잘 못 맞추고 학습안된 데이터도 못맞추는 현상
Overfitting(과적합)
학습데이터에서는 잘 동작하지만 학습 안된 데이터에서는 잘 동작하지 않는 현상
Cross validation
교차 검증
train data, test data가 있을 때 test data는 학습에 사용되서는 안됩니다.
test data를 Hyper Parameter로 사용한다면 그 자체로 치팅입니다.
학습에는 Train, vaildation data만 활용해야 합니다.
고정된 test data를 가지고 모델의 성능을 확인하고 이 test data를 hyper parameter로 업데이트하는 과정을 반복하면서 결국 내가 만든 모델은 test data에만 잘 동작하는 모델이 됩니다. 이 경우에는 test data에 overfitting되어 다른 실제 데이터를 가지고 예측을 수행하면 엉망인 결과가 나오게 됩니다. 이를 해결하고자 하는 것이 Cross validation 입니다.
Bias-variance tradeoff
cost를 최소화하기 한 part를 3가지로 볼 수 있습니다.
1. noise
2. variance (분산)
데이터 내에 있는 error나 noise까지 잘 잡아내는 Highly flexible model에 데이터를 fitting시킴으로서, 실제 현상과 관계 없는 random한 것들까지 학습하는 알고리즘의 경향을 의미합니다. overfitting과 관계되어 있습니다.
지나치게 복잡한 모델로 인한 error.
variance가 큰 모델은 훈련 데이터에 지나치게 적합을 시켜 일반화가 되지 않은 모델입니다.
3. bias (편향)
데이터 내에 있는 모든 정보를 고려하지 않음으로 인해, 지속적으로 잘못된 것들을 학습하는 경향을 말합니다. Underfitting이라고도 합니다.
지나치게 단순한 모델로 인한 error.
model의 bias가 크다는 것은 그 model이 중요한 요소를 놓치고 있다는 뜻입니다.
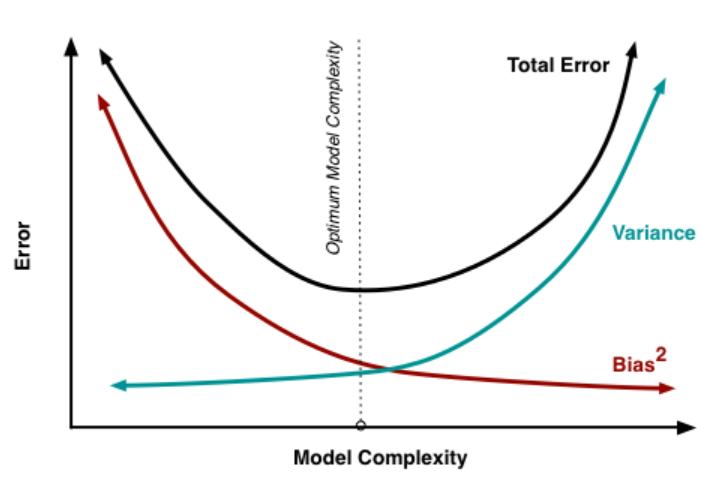
출처: http:// scott.fortmann-roe.com 이상적인 모델은 데이터의 규칙성을 잘 잡아내어 정확하면서도 다른 데이터가 들어왔을 때도 잘 일반화할 수 있는 모델입니다. 하지만 실제 상황에서는 두 가지를 동시에 만족하는 것은 거의 불가능합니다. 따라서 training data가 아닌 실제 데이터에서 좋은 성능을 내기 위해 이런 tradeoff는 반드시 생길 수 밖에 없으며 이는 bias-variance tradeoff라고 합니다.
오류를 최소화하면서 variance와 bias의 합이 최소가 되는 적당한 지점을 찾아야합니다.
Booststrapping
무작위 샘플링을 사용하는 test나 matrix 입니다.
Bagging and Boosting
▶Bagging ( Bootstrapping aggregating)
- Parallel : 여러 모델들을 독립적으로 동작
앙상블의 한 종류.
다수의 model이 Boostrapping으로 훈련되고 있습니다.
기본 분류기는 개별적인 예측이 집계되는 랜덤한 하위 집합(subset)에 적합합니다. (투표 or 평균화)
▶Boosting
- Sequential
분류의 어려운 특징은 특정 training samples에 중점을 두고 있습니다.
Weak Learner를 순서대로 결합하여 강력한 모델을 구축합니다. 각 Learner는 이전의 Weak Learner의 실수로 부터 학습합니다.
예를 들어, 100개 데이터 중 80개의 데이터는 잘 예측하지만 20개의 데이터는 예측에 실패하는 경우
→20개의 데이터에서 잘 동작하는 모델을 만듭니다.
→이를 여러 개의 모델을 만들어서 모델을 합칩니다.
모델을 합칠 때 독립적인 모델로 n개의 결과로 뽑는 것이 아니라 Weak Learner(각각의 모델들)을 Sequencial 하게 합쳐서 하나의 Strong Learner로 만듭니다.
Optimization(최적화) 학습 단위
Batch-Size, Epoch, Iteration 개념을 학습하기 앞서, 예제를 먼저 보겠습니다.
-total(전체 데이터 수) : 2000 -epochs = 20 -batch size = 500(1 Epoch : 모든 데이터 셋을 한 번 학습)
(1 iteration : 1회 학습)
1 epochs = total / batch size - 2000 / 500 = 4 iteration
→ 1 epochs는 데이터 size가 500인 batch로 4개의 iteration으로 나뉩니다.
전체 데이터 셋에 대해 20번의 학습(epochs)이 이루어지고, iteration기준으로 총 80번의 학습이 이루어집니다.
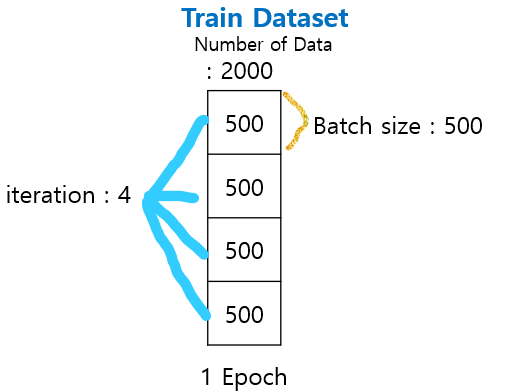
Batch-Size
Batch-Size란 모델 학습 중 parameter를 업데이트할 때 사용할 데이터 개수를 의미합니다. 즉, 연산 한 번에 들어가는 데이터의 크기입니다.
Batch 크기 만큼 데이터를 활용하여 모델이 예측한 값과 실제 정답간의 오차(손실함수)를 계산하여 Optimizer가 paramter를 업데이트합니다.
예를 들어, 전체 트레이닝 데이터 셋을 여러 작은 그룹으로 나누었을 때 하나의 소그룹에 속하는 데이터 수입니다. 전체 트레이닝 셋을 작게 나누는 이유는 트레이닝 데이터를 통째로 신경망에 넣으면 비효율적으로 리소스를 사용하여 학습 시간이 오래 걸리기 때문입니다.
배치 사이즈가 너무 큰 경우 한번에 처리해야 할 데이터 수가 많아지므로 학습 속도가 느려지고 메모리 부족 문제가 발생할 위험이 있습니다. 큰 Batch-Size를 사용하면, 일반화 능력으로 측정하였을 때 모델의 품질이 저하됩니다.
반대로, 배치 사이즈가 너무 작은 경우 적은 데이터를 대상으로 가중치를 업데이트하고, 이 업데이트가 자주 발생하므로, 훈련이 불안정해집니다.
Epoch
훈련 데이터 셋에 포함된 모든 데이터들이 한 번 씩 모델을 통과한 횟수로, 모든 학습 데이터 셋을 학습하는 횟수를 의미합니다.
1 Epoch는 전체 학습 데이터 셋이 한 신경망에 적용되어 순전파와 역전파를 통해 신경망을 한 번 통과한 것입니다.
epoch를 높일수록 다양한 무작위 가중치로 학습하므로 적합한 파라미터를 찾을 확률이 높아집니다.( 손실 값이 작아진다) 그러나, 지나치게 epoch를 높이게 되면, 그 학습 데이터 셋에 과적합(Overfitting)되어 다른 데이터에 대해선 제대로 된 예측을 하지 못할 수 있습니다.
iteration
전체 데이터에 대해 총 Batch의 수를 의미하며, step이라고 부르기도 합니다. 1 epoch를 마치는데 필요한 파라미터 업데이트 횟수라고도 할 수 있습니다.
iteration = (Number of Data / Batch size )
즉, 전체 데이터를 Batch 크기 만큼씩 학습을 하려면 4번 반복해야 합니다. (1 Epoch = 4 iteration)
20 Epochs = 80 iteration
728x90'AI' 카테고리의 다른 글
[AI] Pandas (작성중) (0) 2023.05.12 [AI] Gradient Descent Methods (경사하강법) (0) 2023.04.04 [AI] Neural Network, 활성 함수, MLP (1) 2023.04.03 [AI] 딥러닝 기초 (0) 2023.03.31 [AI] seaborn (0) 2023.03.27